并发(Concurrency)
Golang是一门并发而非并行的语言,在讨论Golang中的并发之前,先理解如下两个问题,
- 什么是并发?
- 并发与并行的区别是什么?
并发
并发指的是同时处理多个任务的能力,下面举个例子:
假设一个人在慢跑,在他晨跑的过程中,告诉他鞋带松了,这个时候他停下来,系好鞋带并重新开始跑
这就是并发的一个典型的例子,这个人有能力做两件事:跑步和系鞋带,也就是说这个人一次能够处理多件事
并行,以及与并发的区别
并行指的是在同一时间做很多事情,这个和并发十分相似,但是它们是有本质区别的
还是上面跑步的那个例子,一个人边跑步边听音乐,也就是说这个人在相同的时间做着两件事请,这个就是并行
从专业的角度来解释一下并行与并发的区别,一个浏览器有各种各样的行为,其中的两个行为就是:页面渲染和文件下载
现在假设我们有一个包含上面两个行为的页面,每一个行为的执行都是相互独立,互不干扰的(这可以通过语言的多线程实现的,比如Java以及Golang)
当该浏览器运行在一个单核的进程中,该进程的上下文环境将会在页面渲染和文件下载之间相互切换,有时处理的是页面渲染;有时候处理的是文件下载。
这个就是并发,并发的进程中处理的任务是周期性交替执行的
还是这个浏览器,不过这个时候是运行在多核上的进程,在相同的时间点,页面渲染和文件下载可能会运行在不同的处理器上核心上,这就是所谓的并发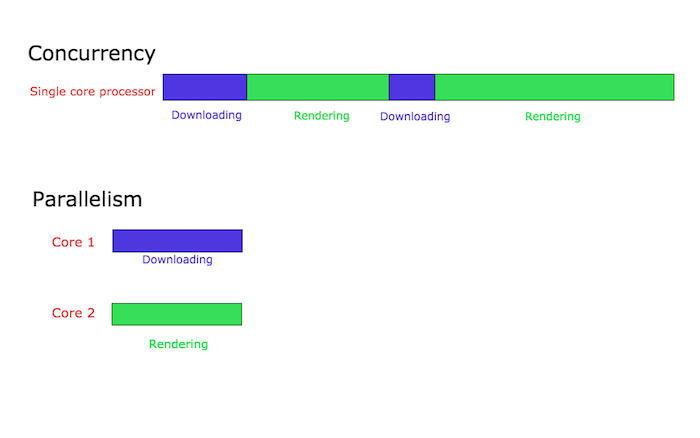
并行的处理任务的时间并不一定总是比并发会,这是因为不同的任务运行可能不得不进行相互通信,
例如,当文件下载完毕后,需要弹出消息提示用户文件下载完毕,这个通信信号发生于文件下载以及页面渲染之间,
这个通信的开销在并发系统中是非常低的,而在并发的多核系统中却是非常高
Goroutines
Goroutines是一个与其他函数/方法并发的函数/方法,Goroutines可以认为是轻量级的线程,
但是相对于线程来说,其占用的资源更少,更廉价,因此一个Go应用中通常包含上千个并发
Goroutines与线程(threads)相比的优势
- Goroutines比线程占用的资源更少,Goroutines只占用几KB大小的栈空间,并且占空间可以依据程序动态调节大小,而线程的栈占用是固定的
- 在部分系统中,Goroutines可以在一个线程中实现多路复用,这样可能出现的情况就是,一个线程中包含上千个Goroutine 如果线程中的某个Goroutine需要等待用户的输入,那么一个新的线程将会被创建,其余Goroutine将会被转移到新的线程中 鉴于这个特性,在并发处理的时候,需要注意处理好Goroutine,最好的方式是添加一个干净的API接口
- Goroutine之间的通信使用channels,它被设置用来防止Goroutine在共享内存的时候发生相互竞争的情况,channel相当于Goroutine之间通信的管道
如何开启Goroutine
在函数或者方法前面添加go关键字,就能开启一个新的Goroutine
package main
import "fmt"
func hello() {
fmt.Println("Hello world goroutine")
}
func main() {
go hello()
fmt.Println("main function")
}
如上所示,在主函数中使用关键字go创建了一个Goroutine执行hello函数,这个时候hello函数以及`main`函数会并发执行,
运行如上脚本,你会发现只执行了main函数,而没有执行hello函数,原因是基于一下两点:
- 当一个新的Goroutine开始的时候,控制语句并没有等待新创建的Goroutine执行完成,就立刻执行创建语句后面的代码,新创建 的Goroutine的任何返回都将会被忽略
- main Goroutine应该在其他的Goroutine执行完成之后再结束,否则其他的Goroutine将会被强制终止执行
因此,为了正确执行上面的语句,可以使用time包的Sleep函数,暂缓main函数的执行
func main(){
go hello()
time.Sleep(1 * time.Second)
}
上面是使用了暂缓执行这种低级的方式来是的Goroutine执行,Channels使用能够阻止main Goroutine在其他Goroutine执行完成之前执行完成
同时启动多个Goroutine
package main
import (
"fmt"
"time"
)
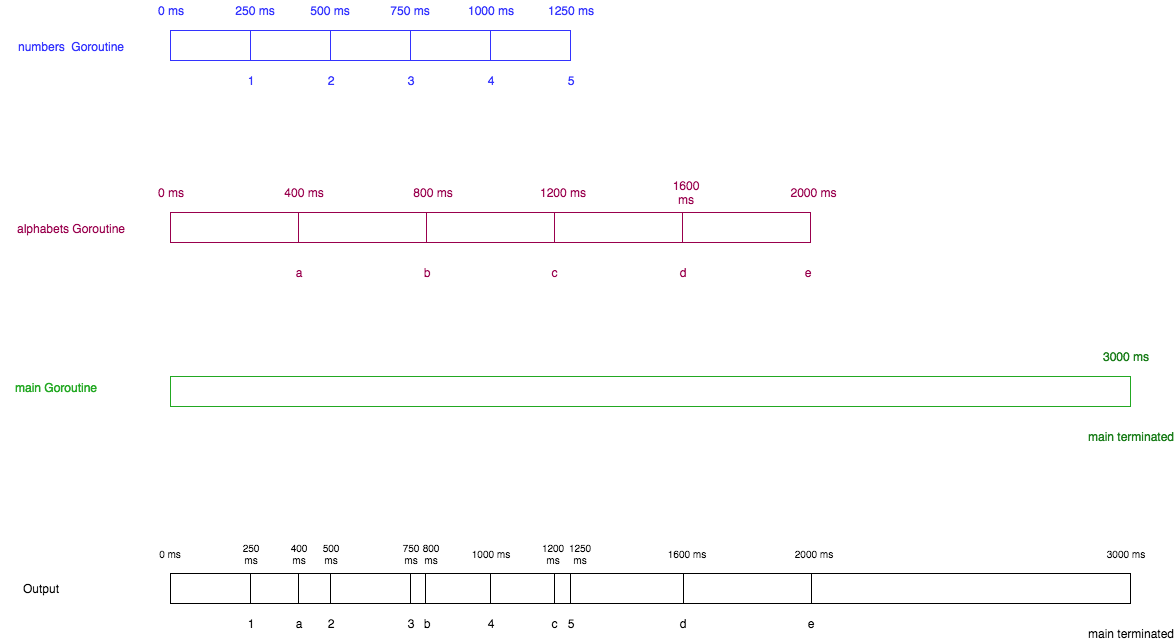
func numbers() {
for i := 1; i <= 5; i++ {
time.Sleep(250 * time.Millisecond)
fmt.Printf("%d ", i)
}
}
func alphabets() {
for i := 'a'; i <= 'e'; i++ {
time.Sleep(400 * time.Millisecond)
fmt.Printf("%c ", i)
}
}
func main() {
go numbers()
go alphabets()
time.Sleep(3000 * time.Millisecond)
fmt.Println("main terminated")
}
运行如上程序,将会固定打印出:
1 a 2 3 b 4 c 5 d e main terminated
Channele
Channel是Goroutine之间进行通信的管道,就像是流水一样,从管道的一道倒管道的另外一端
数据在Channel中也是一样
Channels的声明和定义
每一个管道都与一个数据类型相关联,其他的数据类型将不能够在Channel之中进行传递
声明一个Channel的语句是chan T,使用chan关键字 ,加上Channel中的数据类型,比如:
var a chan int
channel的零值是nil,为零值的channel没有任何用户,因此在定义channel的时候,应该使用make函数
a := make(chan int)
Channels的使用
如下例子表示了向channel发送数据以及从channel中读取数据
data := <- a //从channel中读取数据
a <- data //向channel中写入数据
默认状态下使用channel传递数据是阻塞的,也就是说当将一个数据发送倒channel时,
代码执行将会停留在发送数据声明的语句的地方,直到其他的Goroutine从channel中读取数据,
程序才会继续往下执行,反过来也是一样的,读取数据必须等到有Goroutine向channel中写入数据才会继续执行
基于channel这个特性,Golang才不需要像其他编程语言一样,需要明显的添加锁或者条件语句
对于上面讲Goroutine那个例子进行改造如下:
package main
import "fmt"
func hello(done chan bool) {
fmt.Println("hello world goroutine")
done <- true
}
func main() {
done := make(chan bool)
go hello(done)
<-done
fmt.Println("main function")
}
上面的例子会打印如下:
hello world goroutine
main function
因为当程序运行到<-done语句时,程序发生了阻塞,所以停留在了这个语句,而由于上一个语句go hello(done)
开启了一个新的Goroutine,在hello里面向done这个channel写入了数据,所以main得以继续运行。
死锁
使用channel的时候有一个特别需要注意的地方,就是防止可能出现的死锁的情况,比如:
ch := make(chan int)
ch <- 5
以上情况,向ch中写入了一个数据,但是并没有其他的Goroutine来读取这个数据,程序将会一致停留在向ch中写入数据的地方
因此,一旦程序运行,将会发生一个panic
单向Channels
截至目前为止,我们所讨论的channel都是单向的,输入可以写入也可以读取,除此之外,我们还可以创建单向的channel
,顾名思义,我们可以只写入或者只读取数据,比如:
func sendData(sendch chan<- int) {
sendch <- 10
}
func main() {
sendch := make(chan<- int)
go sendData(sendch)
fmt.Println(<-sendch)
}
在上面的代码中,我们首先创建了一个只具有写属性的channel(使用chan<- int来标识),当我们在主函数中试图从只写的channel中
读取数据(<-sendch)的时候,程序会提示正在执行的是一个非法操作
目前来看一切顺利,但是如果只是创建了一个只写而不能读取的channel有什么意义呢?事实上其用处在于转换,可以将一个双向channel转换成一个单向的channel
func sendData(sendch chan<- int) {
sendch <- 10
}
func main() {
sendch := make(chan int)
go sendData(sendch)
fmt.Println(<-sendch)
}
如上所示,在main Goroutine里面创建一个双向的channel,然后将该channel作为参数,传递到只接收单向channel的sendData函数中,、
所以只读的channel只存在于sendData,在main Goroutine中的channel依旧是双向的
关闭channel以及循环读取
channel的发送者能够提醒接受者将停止数据的发送,接受者能够通过额外的参数判断channel是否已经被关闭
v, ok := <- ch
如果ok == true则表明已经接收到了数据,相反表示,channel已经关闭了,从已经关闭的channel里面读取到的将会是chan所传送数据的零值
func producer(chnl chan<- int) {
for index := 0; index < 10; index++ {
chnl <- index
}
close(chnl)
}
func main() {
ch := make(chan int)
go producer(ch)
for {
v, ok := <-ch
if ok == false {
break
}
fmt.Println("Received", v, ok)
}
}
如上所示,使用close可以关闭channel
Buffered Channels 与工作池(Worker Pools)
当创建一个可缓冲的channel的时候,向channel发送数据,只有在给定的缓冲容量已经满了的情况下才可能出现阻塞的情况
相同的,从一个可缓冲的channel读取数据的时候,只有在channel为空的情况下,才会发生阻塞
可缓冲的channel在创建的时候,需要添加一个额外的容量参数,来表明其容量的大小
ch := make(chan type, capacity)
没有缓冲的channel等价于容量为0的可缓冲channel
func main() {
ch := make(chan string, 2)
ch <- "naveen"
ch <- "paul"
fmt.Println(<-ch)
fmt.Println(<-ch)
}
如上,我们创建了一个容量为2的可缓冲channel,并且向里面写入了两个字符串,在这里没有超过其容量,因此没有出现死锁的情况
下面这个程序能够让我们更好的理解有缓冲的channel所造成的死锁
func write(ch chan int) {
for index := 0; index < 5; index++ {
ch <- index
fmt.Println("successfully wrote", index, "to ch")
}
close(ch)
}
func main() {
ch := make(chan int, 2)
go write(ch)
time.Sleep(2 * time.Second)
for v := range ch {
fmt.Println("read value ", v, " from ch")
time.Sleep(2 * time.Second)
}
}
在上面的程序中
- 先创建一个容量为2,数据类型为int类型的有缓冲的channel
- 创建一个新的Goroutine write,此时暂停程序运行
- 新建的Goroutine开始往ch中写入数据,容量满后造成Goroutine write阻塞
- Goroutine main继续执行,并且开始读取channel中的数据
- 由于设置了读取间隔,所以每读取一个数据,使得channel的容量得以使用,这个时候Goroutine write继续执行
- 程序继续运行,直到channel被关闭
buffered channel的死锁
func main() {
ch := make(chan string, 2)
ch <- "hello"
ch <- "world"
ch <- "deadlock"
fmt.Println(<-ch)
fmt.Println(<-ch)
}
如上所示,由于往容量只有2大小的channel 写入三个数据,当写入第三个的时候,由于没有多余的容量,造成程序无法运行
这个时候就需要另外一个Goroutine从channel中读取数据,使得channel能够有多余的空间,从而使得Goroutine main继续执行
channel的容量指的是,其公共能够存储的值的数量,其长度指的是当前channel中所包含的元素的数量
等待组
等待组主要是用来实现一个工作池, 它经常被用于等待一个Goroutine集合执行完成,在该集合中的所有Goroutine执行完成前,它是阻塞的
举个例子:
func process(i int, wg *sync.WaitGroup) {
fmt.Println("started Goroutine", i)
time.Sleep(2 * time.Second)
fmt.Printf("Goroutine %d ended\n", i)
wg.Done()
}
func main() {
no := 3
var wg sync.WaitGroup
for index := 0; index < no; index++ {
wg.Add(1)
go process(index, &wg)
}
wg.Wait()
fmt.Println("All go routines finished executing")
}
说明:首先创建了一个WaitGroup的变量,WaitGroup就像是一个计数器,Add方法表示需要接受多少个Goroutine完成信号,然后标识整体完成,WaitGroup的计数器会自动增长,
相反当使用Done方法时会自动递减,而Wait方法则会造成阻塞,
直到WaitGroup的计数器的值为0
其中很重要的一点就是,在开启新的Goroutine的时候,传递的WaitGroup必须是传址操作,否则的话,main将会无法接收到其运行结束的信号
工作池的实现
实现工作池的一种方式是使用有缓冲的channel
一般来说,一个工作池就是等待分配任务的线程的集合,其中的线程一旦完成任务,又在等待下一次任务的分配
我们将会使用有缓冲的channel实现这样一个工作池,,给定一个数字,计算其整数位之和
因此需要实现如下的功能:
- 创建一个Goroutine池,监听输入buffered channel并等待任务的分配
- 增加一个任务到输入buffered channel
- 在任务结束后,将一个结果输出到输出channel
- 从输出channel读取并打印结果
实现一个简单的工作池
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
type Job struct {
id int
randomno int
}
type Result struct {
job Job
sumofdigits int
}
var jobs = make(chan Job, 10)
var results = make(chan Result, 10)
func main() {
startTime := time.Now()
noOfJobs := 100
//创建Job,并将其发送到channel jobs
go allocate(noOfJobs)
//循环读取channel results
done := make(chan bool)
go result(done)
//创建工作池并计算job
noOfWorkers := 10
createWorkerPool(noOfWorkers)
<-done
ednTime := time.Now()
diff := ednTime.Sub(startTime)
fmt.Println("total time taken", diff.Seconds(), " seconds")
}
func digits(number int) int {
sum := 0
no := number
if no != 0 {
digit := no % 10
sum += digit
no /= 10
}
time.Sleep(2 * time.Second)
return sum
}
func worker(wg *sync.WaitGroup) {
for job := range jobs {
output := Result{job, digits(job.randomno)}
results <- output
}
wg.Done()
}
func createWorkerPool(noOfWorkers int) {
var wg sync.WaitGroup
for index := 0; index < noOfWorkers; index++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}
func allocate(noOfJobs int) {
for index := 0; index < noOfJobs; index++ {
randomno := rand.Intn(999)
job := Job{index, randomno}
jobs <- job
}
close(jobs)
}
func result(done chan bool) {
for result := range results {
fmt.Printf("Job id %d, input random no %d, sum of digits %d\n", result.job.id, result.job.randomno, result.sumofdigits)
}
done <- true
}
select
select 声明语句主要用于从多个发送/接收的channel中选择一个进行操作,该声明是阻塞的,直到有一个channel以及准备好
如果同时有多个channel准备好了,将会随机选择一个进行操作,该声明类似于switch语句
func main() {
output1 := make(chan string)
output2 := make(chan string)
go server1(output1)
go server2(output2)
select {
case s1 := <-output1:
fmt.Println(s1)
case s2 := <-output2:
fmt.Println(s2)
}
fmt.Println("hello")
}
func server1(ch chan string) {
time.Sleep(2 * time.Second)
ch <- "from server1"
}
func server2(ch chan string) {
time.Sleep(1 * time.Second)
ch <- "from server2"
}
其输出结果为:
from server2
hello
如上所示,由于server1延迟的时间比server2长,因此server2,所以select会选择server2,同时又由于select是阻塞的,
所以主函数的打印在最后执行。
类似于switch,也可以为select设置一个默认的选项,如果执行到select语句的时候,还没有任何一个channel准备好,那么将会执行default
如果给定一个控制select语句块,将会造成死锁
func main(){
select{
}
}
互斥(Mutex)
互斥主要是提供了一种锁的机制,保证在同一个时间点只有一个Goroutine在运行,从而防止竞态条件的发生,使用互斥和channel解决竞态问题
临界区域(critical section)
!并发
[!]
{kind=link}
如上所示,如果Goroutine1与Goroutine2并发执行,那么其结果是1,如果两者之一有一个新完成,然后再执行另外一个,那么结果就是2
也就是说,程序执行的结果,依赖于程序执行中的上下文环境
互斥
在sync包中提供了对Mutex的实现,使用其Lock和Unlock方法,可以防止竞态问题的出现
var mutex = &sync.Mutex{}
mutex.Lock()
x = x + 1
mutex.Unlock()
如果另外一个Goroutine想要使用这个锁,那么这个Goroutine就是阻塞的,必须要等到锁解锁以后才能重新使用
使用Mutex解决竞态问题
如下会产生一个竞态问题,导致输出的结果不确定
package main
import (
"fmt"
"sync"
)
var x = 0
func increment(wg *sync.WaitGroup) {
x = x + 1
wg.Done()
}
func main() {
var w sync.WaitGroup
for i := 0; i < 1000; i++ {
w.Add(1)
go increment(&w)
}
w.Wait()
fmt.Println("final value of x", x)
}
使用Mutex解决这个问题的方式就是加锁,将x = x +1的操作进行加锁,使其在某一个时间点独占
package main
import (
"fmt"
"sync"
)
var x = 0
func increment(wg *sync.WaitGroup, m *sync.Mutex) {
m.Lock()
x = x + 1
m.Unlock()
wg.Done()
}
func main() {
var w sync.WaitGroup
var m sync.Mutex
for index := 0; index < 1000; index++ {
w.Add(1)
go increment(&w, &m)
}
w.Wait()
fmt.Println("final value of x ", x)
}
使用channel解决竞态问题
var x = 0
func increment(wg *sync.WaitGroup, ch chan bool) {
ch <- true
x = x + 1
<-ch
wg.Done()
}
func main() {
var w sync.WaitGroup
ch := make(chan bool, 1)
for index := 0; index < 1000; index++ {
w.Add(1)
go increment(&w, ch)
}
w.Wait()
fmt.Println("final value of x ", x)
}
利用有缓冲的channel在容量使用完毕会造成阻塞的特性,保证了在同一个时间点,只有一个Goroutine对x进行操作